Research
I have a broad interest in machine learning, an important subfield of artificial intelligence (AI). When machine learning models are trained on observational data, the models reflect society as it exists today as well as our own understanding of the world.
The goal of my research are to understand---both theoretically and practically---different stages of learning from data, ranging from data generating process to deployment of the models, and then to leverage this knowledge in developing better learning algorithms. I believe it will not only increase the practical merit of machine learning in our society, but also provide insights into the foundation of learning that paves the way for building a truly intelligent machine, which is an ultimate goal of artificial intelligence.
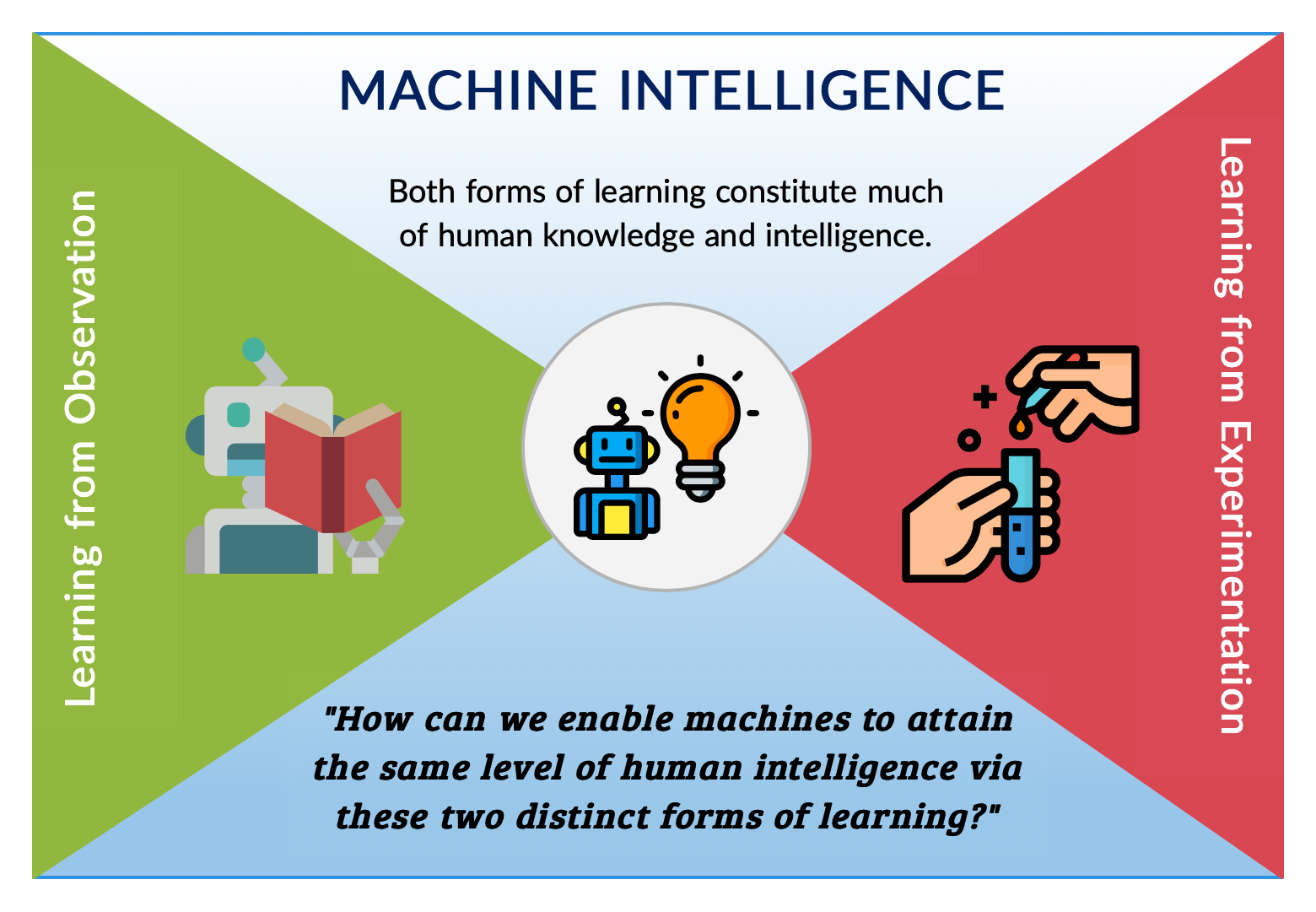
To answer the aforementioned question, I am pursuing several research directions as stepping stones. The current themes of my research are summarized below.
Modern Kernel Machines
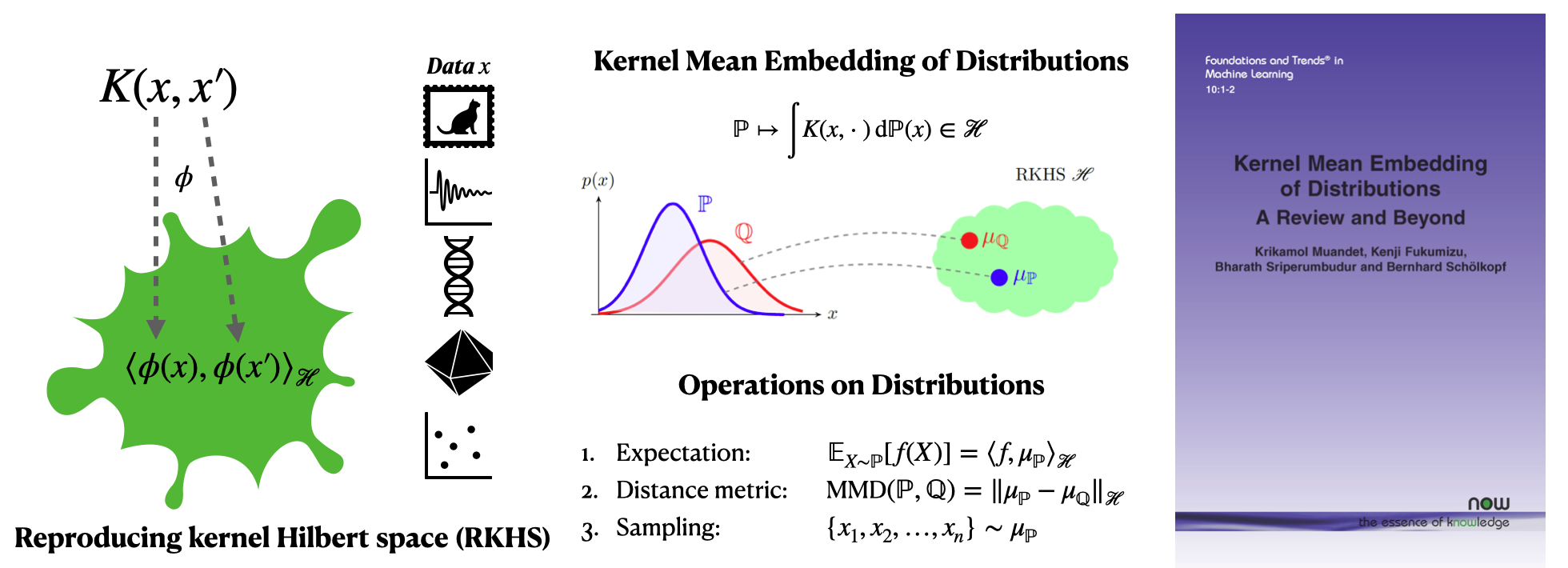
The backbone of kernel methods is a positive definite kernel k(x,x′) which defines a data representation implicitly in a so-called reproducing kernel Hilbert space (RKHS). Besides their mathematical elegance, kernel methods are among the most popular and powerful techniques for predictive machine learning because (i) they are flexible and can work with a variety of data types (e.g., strings, graphs, and groups) in an integrated framework, (ii) we can incorporate prior knowledge about the learning problem through diverse choices of kernel functions, and (iii) there exist abundant learning algorithms that support kernel functions. Recently, the kernel function becomes an important ingredient of neural tangent kernel (NTK) which offers theoretical insights into the training dynamics of deep neural networks. Further, a kernel mean embedding (KME) extends the whole arsenal of kernel methods to probability measures, leading to new research opportunities in deep learning, causality, econometrics, among others. I am constantly pushing for a wide range of new and exciting applications of kernel methods.
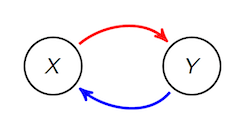
Causality and Counterfactual Prediction
Cause-effect inference is a grand challenge of scientific research. Insights into causal relationships can help assess the consequences of certain interventions such as medical treatments or public policies. The causal understanding of diseases like cancer and possible treatments could ultimately help save million of lives around the world. Furthermore, causal knowledge is a foundation of counterfactual prediction, which is an essential part in decision making. In practice, however, experimental data can be unethical, expensive, or even impossible to collect, so we must rely on observational data which can suffer from the confounding bias. Observational studies are ubiquitous in medical diagnosis, recommendation systems, and personalization. According to the so-called Reichenbach’s principle, the dependence between two random variables implies that either one causes the other, or that they simply have a common cause. Put differently, a straightforward deployment of learning algorithms alone is insufficient for solving causal problems-but it certainly can help. My interest in this direction lies in developing novel algorithms that can achieve better counterfactual prediction from observational data.
Algorithmic Decision Making
While machines that outperform human at prediction tasks have become inexpensive to build, machines that can mimic human judgement and decision is still out of reach. A rapid deployment of predictive models in important sectors such as online advertising, criminal justice, education, and labor market has raised widespread concerns about the societal impact of algorithmic decisions. Complex decisions based on model predictions alone-even when they are perfect-can lead to unintended consequences such as discrimination and unfairness. Unlike a prediction, making a good decision from past data can be challenging because (i) it involves making counterfactual prediction and reasoning about potential outcomes, (ii) there can be many, interrelated factors or alternatives to consider, e.g., self-driving cars, (iii) the impact of the decision may be significant, e.g., health care and justice system, and (iv) the decisions may be subject to a strategic behavior. My goal is to bridge the gap between machine prediction and human judgement by exploring ideas in economics, mechanism design, game theory, and offline reinforcement learning.